Lambda permite ejecutar acciones en un clúster de EKS utilizando la librería del cliente Kubernetes en los lenguajes de programación soportados por AWS Lambda.
Imagen: elaboración propia.
POR EMMANUEL CRUZ, SRE - ALPHA TEAM La posibilidad de gestionar un clúster de Kubernetes mediante código expande las posibilidades para crear integraciones económicas, seguras y eficientes. Por eso, a continuación, te decimos cómo gestionar clústeres de Kubernetes usando funciones Lambda en Amazon Web Services (AWS).
Antes de que sigamos profundizando es necesario mencionar algunos conceptos básicos:
Kubernetes es una plataforma para administrar contenedores, la cual ha revolucionado la forma en que se despliegan y gestionan las aplicaciones que se ejecutan en contenedores.
AWS ofrece un servicio administrado de Kubernetes llamado Elastic Kubernetes Service (EKS) que elimina la necesidad de instalar, operar y mantener un plano de control de Kubernetes propio.
Para gestionar un clúster de Kubernetes se utiliza la herramienta kubectl desde la línea de comandos de nuestra estación de trabajo. Kubectl es la interfaz oficial para comunicarse con el Application Programming Interface (API) de Kubernetes.
Primeras opciones para la interactuar con EKS desde AWS
En ocasiones se requiere ejecutar ciertas tareas en un clúster de EKS desde la misma infraestructura de AWS y para ello el uso de kubectl limita las opciones que se tienen para ejecutarlas.
Algunas de las opciones más comunes que se tienen para interactuar con EKS desde AWS son:
Instancias Elastic Compute Cloud (EC2) con kubectl instalado.
Contenedores usando la imagen de kubectl.
La inconveniencia de estas opciones es que dependen de mantener infraestructura (servidores, orquestadores de contenedores, etc.) y que su administración genera costos.
¿Cómo funciona la gestión de clústeres de Kubernetes mediante Lambda en AWS?
Una alternativa sencilla, segura, rápida y relativamente barata es utilizar funciones AWS Lambda, debido a que es un servicio automático que permite ejecutar código sin aprovisionar o administrar servidores. A continuación, mostramos algunos de los principales conceptos de esta alternativa:
Permisos
La función Lambda requiere algunos permisos de AWS Identity and Access Management (IAM) y Kubernetes Role Based Access Control (RBAC):
El rol de la función Lambda sólo requiere el permiso de IAM eks:DescribeCluster.
Se necesita un Kubernetes RBAC role y rolebinding para la función Lambda con las APIs, acciones y recursos de Kubernetes que podrá utilizar.
Además, se requiere agregar el Amazon Resource Name (ARN) del rol de la función Lambda en el configmap aws-auth del clúster de Kubernetes.
Código
Para lograr que la función Lambda se comunique con EKS mediante código se necesita utilizar la librería del cliente oficial de Kubernetes. Éste permitirá la comunicación con el API de Kubernetes sin la necesidad de usar kubectl. El cliente tiene soporte para varios lenguajes de programación (Go, Python, JavaScript, entre otros).
El código tendrá dos partes:
Una para crear un archivo de configuración kubeconfig.
Otra que usará el cliente para cargar la configuración (kubeconfig), con la que podrá identificarse con el API de Kubernetes y ejecutar la acción deseada.
Ejemplo:
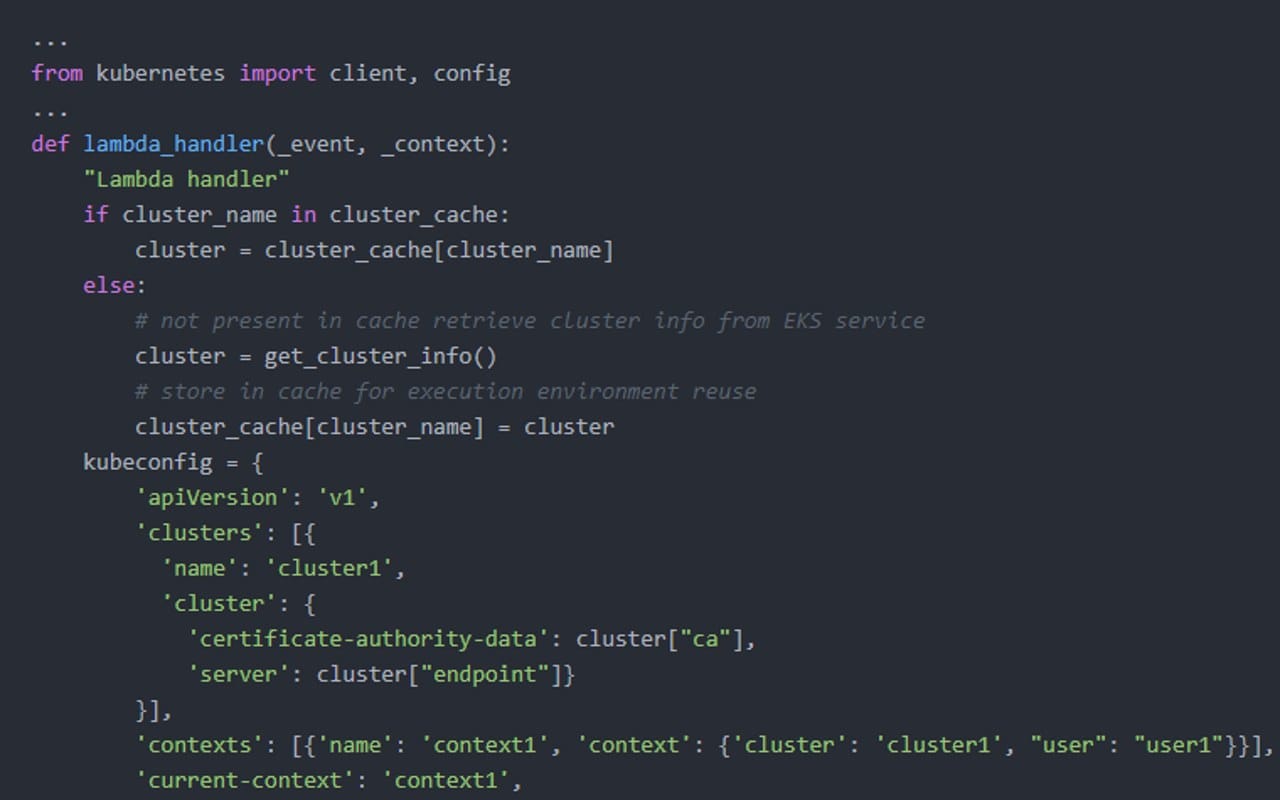
El siguiente fragmento de código en Python lista los pods en el namespace default, en un clúster EKS con endpoint (dirección del API) público.
...
from kubernetes import client, config
...
def lambda_handler(_event, _context):
"Lambda handler"
if cluster_name in cluster_cache:
cluster = cluster_cache[cluster_name]
else:
# not present in cache retrieve cluster info from EKS service
cluster = get_cluster_info()
# store in cache for execution environment reuse
cluster_cache[cluster_name] = cluster
kubeconfig = {
'apiVersion': 'v1',
'clusters': [{
'name': 'cluster1',
'cluster': {
'certificate-authority-data': cluster["ca"],
'server': cluster["endpoint"]}
}],
'contexts': [{'name': 'context1', 'context': {'cluster': 'cluster1', "user": "user1"}}],
'current-context': 'context1',
'kind': 'Config',
'preferences': {},
'users': [{'name': 'user1', "user" : {'token': get_bearer_token()}}]
}
config.load_kube_config_from_dict(config_dict=kubeconfig)
v1_api = client.CoreV1Api() # api_client
ret = v1_api.list_namespaced_pod("default")
return f"There are {len(ret.items)} pods in the default namespace."
print(lambda_handler(None, None))
Básicamente lo que hace la función Lambda es:
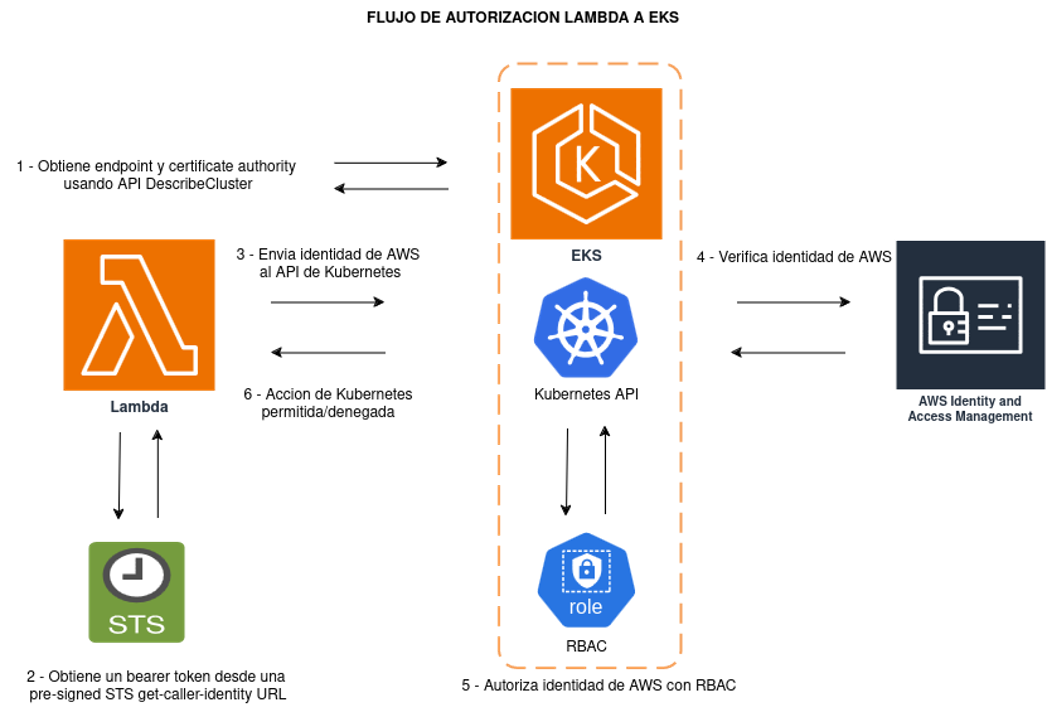
Obtener el endpoint del clúster y su certificado con una consulta al API DescribeCluster.
Genera un token de autenticación llamando a AWS Security Token Service (STS).
Genera un archivo de configuración kubeconfig, usando el endpoint, el certificado y el token.
Carga la configuración de kubeconfig y llama el API de Kubernetes CoreV1Api con el método list_namespaced_pod y namespace default.
En la imagen se puede apreciar el flujo que sigue la función Lambda para poder hacer una solicitud valida al cluster de EKS. Fuente: elaboración propia
El poder de la función Lamda en EKS
Como se puede ver, el uso de una función Lambda permite ejecutar acciones en un clúster de EKS de una manera consistente y segura, utilizando la librería del cliente Kubernetes en cualquiera de los lenguajes de programación soportados por AWS Lambda.
Los casos de uso son demasiados y estarán limitados sólo por el tipo de tareas que se deseen realizar con el clúster de EKS. Algunos de los casos más comunes serian:
Integración en un ciclo de despliegue continuo.
Incremento/reducción de recursos (CPU/Memoria) de los despliegues.
Aumento/disminución del número de réplicas de los despliegues.
Creación/eliminación recursos dentro del clúster (pods, servicios, despliegues, etc.).
El ejemplo del código sólo usa una acción de lectura. La documentación del cliente para Kubernetes tiene el listado completo de APIs y los métodos disponibles para realizar las acciones de lectura, escritura y ejecución.
Por último, cabe mencionar que si se requiere que la función Lambda se conecte a un clúster EKS con endpoint privado o público con Allowlist restringido, la función Lambda necesitara las configuraciones, permisos y reglas correspondientes de redes para poder alcanzar el endpoint del clúster.