POR: CARLOS QUIÑONEZ / BACKEND SOFTWARE ENGINEER
LINQ, por su nombre en inglés Language Integrated Query, es una excelente opción para manipular todos los diferentes tipos de datos de nuestros proyectos, pues se trata de una característica de .NET que nos permite realizar consultas sobre múltiples colecciones de datos de una manera declarativa y utilizando una sintaxis similar a SQL: arreglos, listas, bases de datos, XML, JSON, etc.
Dentro de LINQ existen 3 enfoques diferentes:
- LINQ to Objects: Para consultas sobre colecciones en memoria (listas, arreglos, diccionarios, etc.).
- LINQ to SQL: Para consultar bases de datos SQL Server directamente.
- LINQ to Entities: Parte de Entity Framework (EF) para trabajar con bases de datos relacionales.
Ventajas de usar LINQ sobre consultas SQL tradicionales
LINQ ofrece una sintaxis consistente en múltiples fuentes de datos, validación en el tiempo de compilación y mejoras en la legibilidad del código.
Tipo de consultas en LINQ
LINQ ofrece dos formas principales de escribir consultas:
- Expresiones Lambda: list.Where(x => x.Age > 18).ToList();
- Sintaxis de consulta: from person in list where person.Age > 18 select person;
La utilización de cada una queda a preferencia y necesidades del usuario. En mi caso, veo una opción algo más limpia en la sintaxis de Expresiones Lambda, ya que reduce un poco la cantidad de código necesaria para realizar las consultas, además de ser más flexible para consultas complejas y dinámicas, pero implica el aprendizaje de esta nueva sintaxis, a diferencia de la Sintaxis de consulta, que es bastante similar a SQL y puede ser más legible para consultas simples.
LINQ implementa los mismos tipos de consulta que SQL, siendo los básicos:
- Select: Proyección de datos.
- Where: Filtrado de datos.
- GroupBy: Agrupación de datos.
- Join: Uniones entre colecciones.
¿Cómo podemos optimizar nuestras consultas de LINQ?
Evitar consultas en bucle
Cuando trabajas con LINQ en .NET, un error común que afecta negativamente el rendimiento es ejecutar consultas en bucles. Esto ocurre cuando una consulta se ejecuta repetidamente dentro de un ciclo, lo que genera múltiples llamadas a la base de datos, ralentizando la aplicación. Este problema es particularmente evidente en aplicaciones que interactúan con bases de datos o colecciones grandes.
Ejemplo Problemático: Uso de Where() en Bucles
Considera el siguiente código donde se busca si existen ciertos elementos en una base de datos usando Where():
foreach (var id in ids)
{
var exists = dbContext.Users.Where(u => u.Id == id).Any();
if (exists)
{
// Realizar alguna acción
}
}
En este caso, Where() se ejecuta una vez por cada iteración del ciclo, lo que resulta en múltiples consultas a la base de datos. Si la lista ids tiene, por ejemplo, 100 elementos, entonces se enviarán 100 consultas a la base de datos, lo que afecta significativamente el rendimiento.
Alternativa: Uso de Any() Fuera del Bucle
Una forma eficiente de evitar este problema es realizar la consulta fuera del bucle, trayendo todos los datos necesarios de una vez, y luego procesarlos en memoria. Un buen enfoque es utilizar métodos como Any(), Contains(), o FirstOrDefault() para evitar consultas repetidas.
Solución con Any()
var existingIds = dbContext.Users
.Where(u => ids.Contains(u.Id))
.Select(u => u.Id)
.ToList();
foreach (var id in ids)
{
if (existingIds.Any(eid => eid == id)
{
// Realizar alguna acción
}
}
Aquí, la consulta se ejecuta sólo una vez, obteniendo todos los Id de los usuarios que coinciden con los elementos de la lista ids en una sola llamada a la base de datos. Luego, el ciclo simplemente trabaja sobre los datos en memoria, mejorando significativamente el rendimiento.
Lazy Loading vs Eager Loading
Al trabajar con Entity Framework en .NET existen dos formas principales de cargar datos relacionados: Lazy Loading e Eager Loading. La diferencia clave está en cuándo y cómo se traen esos datos de la base de datos.
- Lazy Loading (Carga Perezosa)
En Lazy Loading, los datos relacionados no se cargan al principio. Se traen sólo cuando los necesitas, es decir, cuando accedes a esas propiedades en tu código.
Ejemplo sencillo:
Imagina que tienes un usuario que tiene varias órdenes. Si solo quieres ver la información del usuario no necesitas traer sus órdenes al principio. Pero si en algún momento preguntas por las órdenes, en ese momento Entity Framework va a buscar esos datos.
var user = dbContext.Users.Find(1) // Sólo trae los datos del usuario
var orders = user.Orders; // Ahora se hacen consultas para traer las órdenes
¿Cuándo usarlo?:
- Cuando no siempre vas a necesitar los datos relacionados.
- Cuando quieres optimizar el uso de memoria y no cargar datos innecesarios.
Problema:
Si haces esto dentro de un ciclo o con muchos datos relacionados puedes terminar haciendo muchas consultas a la base de datos, lo que ralentiza tu aplicación.
- Eager Loading (Carga Ansiosa)
En Eager Loading los datos relacionados se traen de inmediato en una sola consulta. Usas el método Include() para decirle a Entity Framework que también cargue las entidades relacionadas desde el principio.
Ejemplo sencillo:
Si sabes que siempre vas a necesitar las órdenes del usuario puedes cargarlas desde el inicio para evitar consultas adicionales.
var user = dbContext.Users
.Include(u => u.Orders) // Carga el usuario y sus órdenes de una vez
.FirstOrDefault(u => u.UserId == 1);
¿Cuándo usarlo?:
- Cuando sabes que siempre vas a necesitar los datos relacionados.
- Cuando quieres evitar hacer múltiples consultas más adelante.
Problema:
Puedes cargar más datos de los que necesitas, lo que consume más memoria y puede hacer que la consulta inicial sea más lenta.
Uso de Select y proyecciones
Reduce la cantidad de datos seleccionados usando Select para devolver sólo las columnas necesarias, mejorando el rendimiento.
Uso de AsNoTracking() en Entity Framework
Cuando trabajas con Entity Framework, por defecto, las entidades que recuperas de la base de datos son rastreadas por el contexto. Esto significa que Entity Framework mantiene un registro de los cambios que hagas en las entidades para que, si decides guardar esos cambios, pueda generar las consultas UPDATE necesarias. Sin embargo, cuando sólo necesitas leer datos y no tienes la intención de modificarlos, el rastreo de entidades es innecesario y consume recursos.
El método AsNoTracking() te permite deshabilitar el rastreo de cambios en las entidades, lo que mejora el rendimiento en consultas de sólo lectura.
Ejemplo de uso:
var user = dbContext.Users
.AsNoTracking()
.Where(u => u.IsActive)
.ToList();
En este ejemplo, AsNoTracking() le indica a Entity Framework que no necesita rastrear los cambios de los usuarios recuperados, lo que hace que la consulta sea más rápida y eficiente en términos de memoria.
Ventajas de AsNoTracking():
- Mejor rendimiento: Al omitir el rastreo de cambios se reducen los costos de procesamiento, especialmente cuando estás cargando una gran cantidad de datos.
- Menor consumo de memoria: Entity Framework no almacena las entidades en su cache, lo que significa que consume menos memoria.
- Ideal para consultas de solo lectura: Cuando únicamente necesitas consultar y mostrar datos sin necesidad de modificarlos AsNoTracking() es perfecto.
¿Cuándo usarlo?:
- Consultas de solo lectura: Ideal cuando únicamente quieres mostrar datos, como en reportes o visualización de información.
- Operaciones de alto rendimiento: Si estás ejecutando muchas consultas, o consultas que traen grandes volúmenes de datos, AsNoTracking() ayuda a evitar la sobrecarga.
¿Cuándo no usarlo?:
- Cuando necesitas modificar las entidades: Si planeas hacer cambios a las entidades recuperadas y luego guardarlos no debes usar AsNoTracking(), ya que el contexto de Entity Framework no detectará esos cambios automáticamente.
Depuración de Consultas Complejas en LINQ
Al trabajar con consultas LINQ en .NET las consultas complejas pueden convertirse en una fuente de problemas de rendimiento. A continuación, te presento algunas técnicas para descomponer y analizar estas consultas, con el fin de identificar posibles cuellos de botella y optimizar su rendimiento.
- Divide la Consulta en Partes Más Pequeñas
Una de las mejores maneras de depurar una consulta compleja es dividirla en partes más simples. Esto te permite aislar las secciones que podrían estar afectando el rendimiento.
Ejemplo:
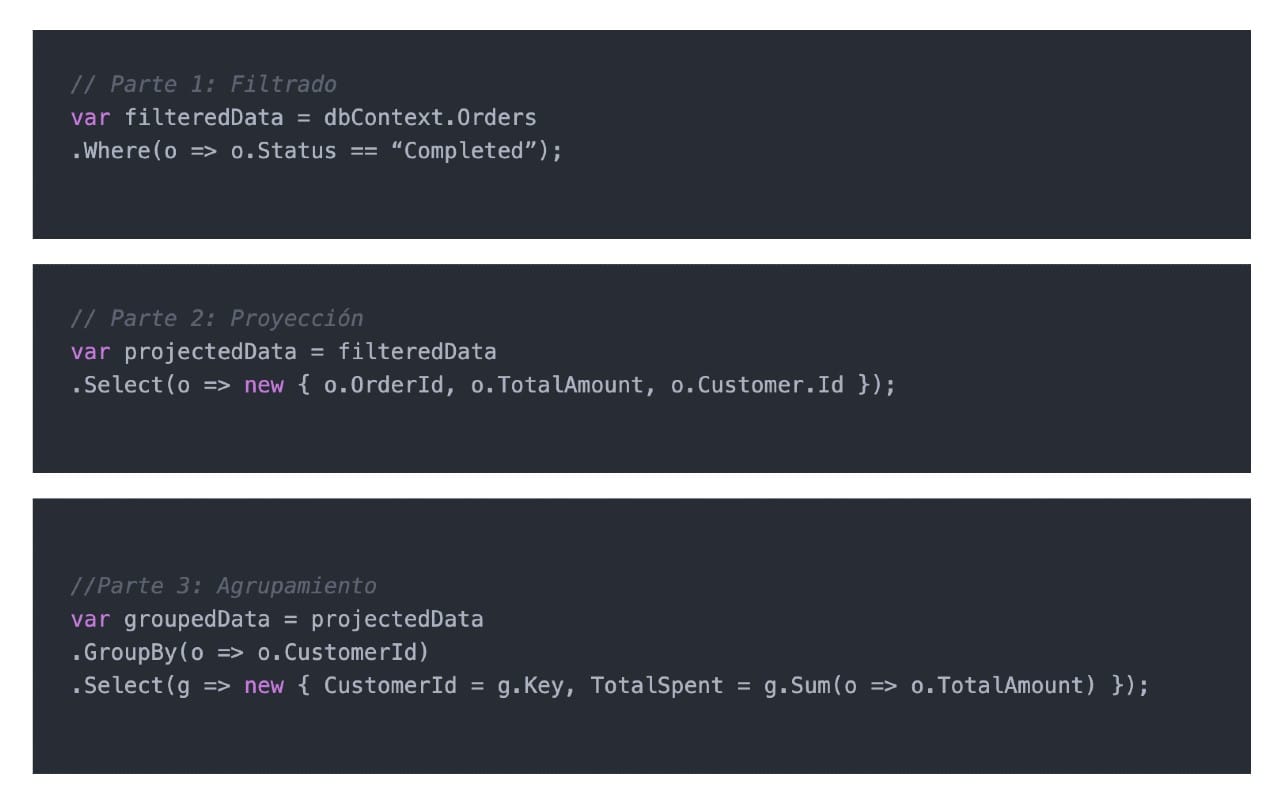
Si tienes una consulta compleja con varios Where, Join y GroupBy, intenta dividirla:
// Parte 1: Filtrado
var filteredData = dbContext.Orders
.Where(o => o.Status == “Completed”);
// Parte 2: Proyección
var projectedData = filteredData
.Select(o => new { o.OrderId, o.TotalAmount, o.Customer.Id });
//Parte 3: Agrupamiento
var groupedData = projectedData
.GroupBy(o => o.CustomerId)
.Select(g => new { CustomerId = g.Key, TotalSpent = g.Sum(o => o.TotalAmount) });
Ventajas:
Al dividir la consulta puedes ejecutar cada parte de forma independiente y verificar su rendimiento.
Facilita la identificación de la parte exacta que podría estar generando problemas.
- Ver el SQL Generado
Entity Framework traduce tus consultas LINQ a SQL. A veces el SQL generado no es tan eficiente como esperas, especialmente si la consulta LINQ es compleja. Ver el SQL resultante puede ayudarte a detectar ineficiencias.
Para ver el SQL generado puedes usar:
var query = dbContext.Orders
.Where(o => o.Status == “Completed”)
.Select(o => new { o.OrderId, o.TotalAmount });
.ToQueryString(); // Muestra la consulta SQL generada
Console.WriteLine(query);
Revisar el SQL te permitirá ver si:
- Se están generando demasiadas consultas (problema N+1).
- Se omiten índices.
- Hay joins o subconsultas innecesarias.
- Analiza el Plan de Ejecución
Una vez que tengas la consulta SQL generada puedes analizar el plan de ejecución en la base de datos. Este plan muestra cómo la base de datos ejecutará la consulta y te permite identificar cuellos de botella, como:
- Falta de índices.
- Operaciones de escaneo completo en tablas grandes.
- Uniones innecesarias.
Para hacerlo:
- Toma la consulta SQL generada.
- Ejecuta el plan de ejecución en tu sistema de gestión de bases de datos (por ejemplo, con EXPLAIN en SQL Server o PostgreSQL).
- Analiza los tiempos de ejecución y las operaciones costosas.